
If you are on an e-commerce site, search is probably the most important thing, so it is good to get it done well.
This is the journey we will go on where we have basic search which is filters, you can do Q objects, I would say the next step is Postgres and then after that you have hosted solutions and there are many. Here are two, Algolia and swift type. And then you have full blown services like Elasticsearch.
I am assuming you have knowledge of how Django works so I will be only focusing on implementing search functionality on your Django site.


1. Basic Search
Let's assume we already have a model City which has with fields name and country. I will explain basic search very quickly as this is very simple and no configuration is required to use it. You can use basic search in basic websites but definitely not in a ecommerce site or where search plays a vital role.Filtering
City.objects.filter(name__icontains='Boston')Chaining Filters (ANDs)
City.objects.filter(name__icontains='Boston').exclude(state__icontains='NY')Q Objects (ORs)
from django.db.models import Qreturn City.objects.filter(Q(name__icontains='Boston') | Q(state__icontains='NY'))
2. Full-text Search
This is what we are used to in the real world. I am talk through how it works and how to implement it and built-in Django support.Full-text search is to search documents that satisfy a query and sort by relevance. Here document can be referred to a large body of text, could be a book, newspaper article, email, anything. Query is not just dumb comparisons and can add also abstractions to decipher meaning of search. Relevance is the million $ question, how to show Google-like results even if user not type what they actually mean, or has typos, etc. So, in order to achieve great relevant results let's look into the features of full text search that enables us to do so.
Full Text Search Features

Rankings - get at relevance, add weights so maybe city name more important than state? Especially, when search on many different fields or items. Lots of tuning.
Indexes - Performance. If running a filter on 1m lines of a database, not fast. So can pre-process and create index. Issues? Is data static (use a GIN) or dynamic (GiST). How often need to update? Tradeoffs...
Phrase Search - match “jumping quickly” with “to jump very quickly”
Stop Words - words so common not relevant like “the”, “s”, “es”, etc.
Stemming - reduce words to base stems, an algorithm, so “fishing” “fishes” “fisher” -> fish “Ran” stems to “run”.... “Slept” to “sleep”. It is language specific and intelligent not just contains/matching query
Accent/multiple language support - nice to add
JSON[B] - if manipulating/searching JSON, use JSONB for performance (no whitespace, no duplicate keys, sorted keys). Refer to docs for more!
Stemming - reduce words to base stems, an algorithm, so “fishing” “fishes” “fisher” -> fish “Ran” stems to “run”.... “Slept” to “sleep”. It is language specific and intelligent not just contains/matching query
Accent/multiple language support - nice to add
JSON[B] - if manipulating/searching JSON, use JSONB for performance (no whitespace, no duplicate keys, sorted keys). Refer to docs for more!
Preparing for a Efficient Search

This is how it works. It preprocesses the search. It looks at the text and says this is a number, phrase or email and Postgres uses a parser. Then it turns it into Lexemes. This step normalizes the string, where upper and lower cases are the same. Remove suffixes. Different spellers -- colors without a U or with a U. Once we have this preprocessed document, we can optimize search on it by adding an indexes.
Let me give you a little bit more examples. That's the heart of it. These are the two data types that Postgres give us. tsvector (preprocessed documents) and tsquery (processed queries). We can apply intelligence to both sides of the equation to have better search.

The quick brown fox jumps over the lazy brown dog is a standard phrase because it uses every letter in the English language. This is preprocessing the document. This is how it looks to the computer. It is taking lexemes. Brown's position is the third position but if you look at jump the actual word is jumps but it made it into jump. That's the stem. The position matters for relevancy. This is just a simple way of showing how it is changed by the computer to be into a tsvector.
We can do the same thing with queries. This is to normalize and check against our vector. Again, using the same phrase. There is a match operator which is double @. If you typed in a dog that would match dogs because it knows to strip out the S, dog food would not because that is not a relevant phrase, jumping would because it sees jump and it can take the stim and do jumping. There is a lot you get out of the box and you need to customize these over time.

And then there is four default operators. You are always going to use a match.

Performing Search using PostgreSQL

There are 5 classes built into Django to work with PostgreSQL FTS and save us a lot of work. The big assumption is you have Django set-up with Postgres. Let's assume it's installed.
1. Search Vector

This is the ability to add multiple fields so replicate previous with name and state.
In this case, it doesn't make as much sense with four city fields but this works and if you added a real document, you would get better results. You can see that you can add in multiple fields here as a search vector. Just use this code and try it out and it will work for you.
2. Search Query
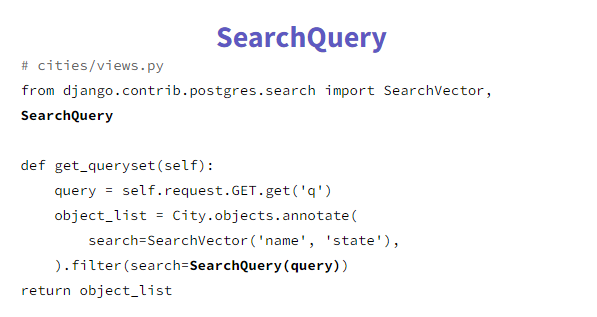
We can add stemming or stop words. It will apply logic to our query, and apply a stemming algorithm. It translates user query into an object that can be compared against search vector.
3. Search Rank
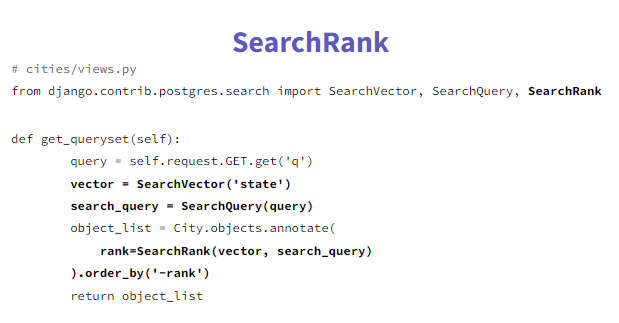
It is a ranking function from Postgres based on proximity, how close terms are in the document.
4. Weighted Queries
Every field may not have the same relevance in a query, so you can set weights of various vectors before you combine them. The weight should be one of the following letters: D, C, B, A. By default, these weights refer to the numbers 0.1, 0.2, 0.4, and 1.0, respectivelyvector = SearchVector('state', weight='A') + SearchVector('name', weight='B')
5. SearchVectorField
If this approach becomes too slow, you can add a SearchVectorField to your model. Then, you can then query the field as if it were an annotated SearchVector.It would be a cool talk to compare Postgres with Elastic. But I will keep it for next blog.
Refer to the docs, if you want to go more in depth https://docs.djangoproject.com/en/4.0/ref/contrib/postgres/search/


Post a Comment
Let's make it better!
Comment your thoughts...